Dolly2 and LangChain: A Game Changer for Data Analytics

Who hasn’t heard of ChatGPT !
Large Language Models (LLMs) belong to a family of foundation models that are trained on vast amounts of data to learn semantic relationships. They are not only more accurate but also faster to train compared to older model families such as Transformers, RNNs, and LSTMs. Numerous LLMs have recently been introduced by major companies, including GPT-2, 3, 4 (OpenAI), LaMDA (Google), BLOOM (HuggingFace), LLaMA (Meta), Dolly (Databricks), and many more. Most of these models have billions of parameters and are trained on trillions of tokens.
One key characteristic (or drawback) of nearly all these LLMs is that they are not open-source, and using them for commercial purposes requires paying a license fee to the parent company. This can result in substantial costs for individuals or brands intending to use these models. However, this has changed with Dolly2.0, an LLM provided by Databricks. It is 100% open-source, comes with training code, datasets, model weights, and an inference pipeline that are all suitable for commercial use.
The evolution of Dolly2.0

Dolly 1.0 preceded Dolly 2.0 and was actually based on LLaMA by Meta. Since it was built on a non-open-source LLM, it was a commercial model which had to be licensed. The key transition from Dolly 1.0 to Dolly 2.0 is that Dolly 2.0 is not based on LLaMA, but rather on the Pythia model family from EleutherAI, which it is fine-tuned from. It is trained on 300 billion tokens and has over 12 billion parameters.
One of Dolly 2.0’s most significant contributions to the AI world is that not only are these models open-sourced, but their training datasets, models, and inference pipelines are as well. The entire dataset can be accessed here. Another interesting fact when comparing it with the GPT family from OpenAI is that OpenAI had 40 people creating the training dataset, while Databricks employed 5,000 of their workers to create this training dataset of 15,000 tasks. These tasks include brainstorming, classification, closed QA, generation, information extraction, open QA, and summarization. Additionally, you can incorporate your own data to further fine-tune the model according to your specific requirements.
We believe models like Dolly will help democratize LLMs, transforming them from something very few companies can afford into a commodity every company can own and customize to improve their products — Databricks
Read the blog on Dolly2 by Databricks here.
The Dolly2 Model
There are three versions of Dolly2 model — one with 3Billion parameters, one with 7Billion and one with 12Billion. The choice of running these models is dependent on the computing resources you have, and how accurate you want your model to be.
Working Code: How to run the model for your use case
Environment: Google Colab Pro (Make sure you have a high RAM environment/runtime for running this)
Model: dolly-v2–7B (Dolly2.0 with 7Billion Parameters)
You can choose to run a 3 Billion (dolly-v2–3B) or 12 Billion parmaeter model (dolly-v2–12B) too depending on the computing resources. All models are hosted on the HuggingFace repository here
Source: Thanks to the awesome tutorials by Sam Witteveen
Install Dependencies
Build Pipeline
Install dependencies
Start using the model — fully opensourced, no APIs
The response to above query is below (output):
[{'generated_text': 'This is very much open for debate.
The ability to adapt to different situations, good technique, fearlessness,
killer instinct, aggression and quality of cover drive are the traits
that one can look at for Dhoni. However, the biggest compliment that can be
paid to him is his leadership and good vision to finish games off.
There are also examples of him playing some good knocks in stiff conditions
in the middle overs but the biggest knock of the ball for him will always be
the six off Hashim Amla at the Wanderers Stadium in Johannesburg in 2008.
He has also been successful in the World T20s and ODIs which he started off
pretty well.'}]The entire notebook can be accessed at the colab link here — feel free to use this code, just copy the notebook in your Google Drive, allocate a good runtime if you can and run this. Congrats ! You have your own Q&A model.
The next post will talk about how to incorporate your own data for a customized fine-tuning on a specific dataset.
Taking Language Models to the next level — The LangChain Framework

LangChain is an open-source framework designed to integrate Large Language Models, such as GPT-3.5, GPT-4, LLaMA, and Dolly2, with external sources of computation and data. The framework is currently available as a Python and TypeScript package.
LangChain is built to customize any LLM (e.g., GPT-4, Dolly2) with your own data, allowing the model to be fine-tuned on any custom dataset. This goes beyond merely pasting data into a ChatGPT-like prompt, where you can ask questions based on the pasted data. Instead, LangChain can connect to your database, a corpus of large documents, a book, or PDF files, or just about anything. Moreover, LangChain can also initiate actions like sending an email, connecting to an API, or interfacing with a third-party tool.
How does LangChain work?
The first step in LangChain is document parsing — it takes in your document corpus, convert it into chunks and store the embeddings into a VectorStore which is a vector representation of your data.
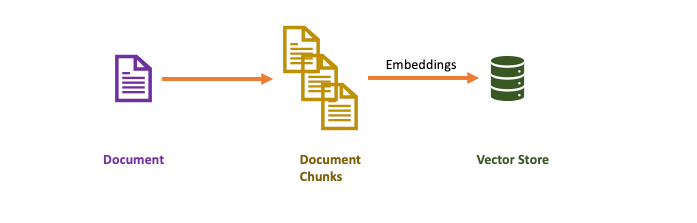
The LangChain Pipeline
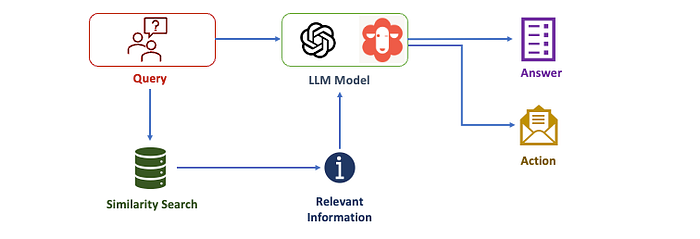
The initial query is passed to the framework, which in turn is passed on to the selected language model, and the vector representation is sent to the vector store for a similarity search. This allows it to retrieve relevant chunks of information from the vector database and feed them back to the language model. Consequently, the language model has both the initial question and the relevant information from the custom database, enabling it to generate an answer and/or take an action, such as sending an email.
The ‘Chain’ in the LangChain framework can assemble multiple components, such as models or datasets, to solve a specific task, allowing it to perform more complex tasks. One component could be responsible for extracting one part of the information, while a second component extracts another part, and a third component stitches both pieces of information together. All three components could be using different models that are most accurate for their respective tasks.
Why is this a revolutionary step in the field of Data Analytics?
The ability to connect to any model, ingest any custom database, and build upon a framework that can take action provides numerous use cases for the LangChain framework. You can use it to load your specific course material or entire syllabus and generate responses to questions, facilitate money transfers, book flights, or even perform coding and data analysis.
One of the great use cases is connecting the LangChain framework to your transaction data or marketing data, and using it to ask questions. Think of it as the next generation in analysis, where you won’t need coders proficient in SQL or Python to query the database. Instead, a non-technical person or a marketing manager can simply ask questions like “Who is the best customer for this campaign?” or “Show me the sales trend of my platinum-tier customers for each store.” Moreover, since the LangChain framework can take actions too, you can connect it to APIs or third-party campaign execution platforms, enabling you not only to obtain data about your best customers but also to execute your campaigns!
This is the trigger that will change the entire field of Data Analytics !
Working Code: How to run LangChain framework
The codes and examples are borrowed from few blogs and tutorials on the internet, specially from Rabbitmetrics.
Environment: Google Colab Pro
Model: OpenAI GPT-3-turbo. You can use GPT-4 too, but sometimes the servers are too busy or slow.
Part 0: Installing Dependencies
Also, make sure you have your OpenAI API key — if you don’t have one, get it from API keys — OpenAI API. Store it in the variable openai_api_key
Part 1: Large Language Model — Wrappers
This is to show how the langchain package handles LLMs. We will use a non-chat model ‘text-davinci-003’ for this purpose
Let’s ask if the model knows about IPL
from langchain.llms import OpenAI
llm=OpenAI(model_name = 'text-davinci-003',openai_api_key=openai_api_key)
llm("explain Indian premier league in 200 words")Pasting the output as plain text as I am facing some issues with word wrapping here :(
Output :
Indian Premier League (IPL) is a professional Twenty20 cricket league in India contested during April and May of every year by teams representing Indian cities. It was founded by the Board of Control for Cricket in India (BCCI) in 2008, and is the most-attended cricket league in the world. The IPL is the most-watched cricket league in the world and ranks sixth among all sports leagues. Each team plays against the others twice, once at home and once away, and the top four teams qualify for the playoffs. The IPL culminates with the final match in May, in which the winner is crowned the Indian Premier League champion team.
Interacting with the Chat Models — GPT-3.5 or GPT-4
The chat models available on OpenAI take in 3 parameters — an AI message, a Human Message and a System Message (to configure the system or the model). To use the chat model API , we need to combine the human message and the system message in a list, and give it as an input to the chat model
from langchain.schema import(AIMessage, HumanMessage, SystemMessage)
from langchain.chat_models import ChatOpenAI
#Define the model
chat = ChatOpenAI(model_name = "gpt-3.5-turbo", temperature = 0.3,openai_api_key=openai_api_key)
messages = [
SystemMessage(content="You are an expert data scientist"),
HumanMessage(content="Write a Python script to train a neural network on a simulated data")
]
response = chat(messages)Output:

Voila — It can write full fledged code with just a few lines of text
Part 2: Prompt Templates
Prompt templates are a great functionality provided by LangChain framework which takes a segment of text and within it, inserts a user input. The prompt can then be formatted with the user input and fed to the language model to generate the output
Here is the code snippet of how a prompt is written
from langchain import PromptTemplate
template = """
You are an expert data scientist with an expertise in building deep learning
models.
Explain the concept of {concept} in 3 lines
"""
prompt = PromptTemplate(
input_variables = ["concept"],
template=template
)The input variable {concept} can take anything which will be injected in the template text at the right location. Here is an example:
llm(prompt.format(concept =”embeddings”))
Output:

If the above image is not visible, here is one specific output
llm(prompt.format(concept ="embeddings"))Output:
Embeddings are low dimensional representations of high dimensional data, such as text or words, that capture the underlying semantics of the data. These representations are learned through neural networks, and can be used as features in various machine learning models for tasks such as text classification and sentiment analysis.
Part 3: Chains
Connecting everything !
A chain is a composite structure that combines an input language model and a prompt template to create an interface. This interface processes user input and generates a response from the language model. Essentially, it works like a composite function with the prompt template as the inner function and the language model as the outer function.
Moreover, it is possible to construct sequential chains where the output generated by the first chain is used as input for the second chain, enabling a multi-layered processing system.
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
##Run the chain specifying only the input variable
print(chain.run("Autoencoder"))Output:
Autoencoders are a type of neural network which are used for unsupervised learning. They learn to compress data using an encoding layer, which is then decoded back to its original form. Autoencoders are used for feature extraction, dimensionality reduction, and anomaly detection.
Let’s write a second prompt
second_prompt = PromptTemplate(
input_variables = ["ml_concept"],
template="Turn the concept description of {ml_concept} and explain it to me like I am five in 300 words"
)
chain_two = LLMChain(llm=llm, prompt=second_prompt)Combining the two chains
from langchain.chains import SimpleSequentialChain
overall_chain = SimpleSequentialChain(chains=[chain, chain_two], verbose=True)
##Run the chain specifying only the input variable for the first chain
explanation = overall_chain.run("Autoencoder")
print(explanation)Output:
> Entering new SimpleSequentialChain chain…
Autoencoders are a type of deep learning neural network that take an input and attempt to reconstruct it at the output. They are used for data compression, feature learning, and anomaly detection. Autoencoders are trained using an unsupervised learning algorithm, meaning they learn without labels or targets.
Autoencoders are a special type of computer program that can take in a bunch of information and try to reconstruct it. For example, if you had a picture of a cat, the autoencoder could take the picture, break it down into its individual pieces, and then put it back together again.
Autoencoders can be used to do lots of different things. For example, they can be used to make data smaller, so it takes up less space. They can also be used to learn about different features in the data, like if a picture has a cat in it or not. Finally, they can be used to detect unusual things, like if something doesn’t look quite right.
Autoencoders are trained using an unsupervised learning algorithm. This means that they learn without a teacher telling them what to do. Instead, they look at the data and figure out how to process it on their own.
In summary, autoencoders are a special type of computer program that can take in information and try to reconstruct it. They can be used for data compression, feature learning, and anomaly detection. They are trained using an unsupervised learning algorithm, meaning they learn without labels or targets
> Finished chain.
Autoencoders are a special type of computer program that can take in a bunch of information and try to reconstruct it. For example, if you had a picture of a cat, the autoencoder could take the picture, break it down into its individual pieces, and then put it back together again.
Autoencoders can be used to do lots of different things. For example, they can be used to make data smaller, so it takes up less space. They can also be used to learn about different features in the data, like if a picture has a cat in it or not. Finally, they can be used to detect unusual things, like if something doesn’t look quite right.
Autoencoders are trained using an unsupervised learning algorithm. This means that they learn without a teacher telling them what to do. Instead, they look at the data and figure out how to process it on their own.
In summary, autoencoders are a special type of computer program that can take in information and try to reconstruct it. They can be used for data compression, feature learning, and anomaly detection. They are trained using an unsupervised learning algorithm, meaning they learn without labels or targets
The complete code is shared on a Google Colab Notebook here — make sure to change the API Key
